Introduction and Background
I hate boilerplate code. 😠 You know that feeling when you are in the zone, you know exactly what to write - perhaps its a 3D loop, a DataFrame process, and then you sigh as you have to quickly type out the correct syntax so you can get to the REAL stuff?
Yep, we all do 😄 I’m trying to write a JARVIS-like code generator, where you can type commands into the console and violá! The code is generated and fed back to you in the console!
My plans are to eventually strengthen the code printing abilities and build this into a module of a personal JARVIS, fully built with it’s own voice and with voice recognition, an ongoing project of mine, as I have yet to find a good personal assistant package - if you know one that has a large and active community - please let me know in the comments, everything I’ve found on GitHub is old or near empty)
The Code
Currently the package supports for loops, class skeletons, regex’s, and definitions (functions). So, you wanna see the code? YOU REALLY WANNA SEE IT? HERE IT IS!!!!
# imports
import nltk
# text 2 int interpretation - very important to this programm
def text2int(textnum, numwords={}):
if not numwords:
units = [
"zero", "one", "two", "three", "four", "five", "six", "seven", "eight",
"nine", "ten", "eleven", "twelve", "thirteen", "fourteen", "fifteen",
"sixteen", "seventeen", "eighteen", "nineteen",
]
tens = ["", "", "twenty", "thirty", "forty", "fifty", "sixty", "seventy", "eighty", "ninety"]
scales = ["hundred", "thousand", "million", "billion", "trillion"]
numwords["and"] = (1, 0)
for idx, word in enumerate(units): numwords[word] = (1, idx)
for idx, word in enumerate(tens): numwords[word] = (1, idx * 10)
for idx, word in enumerate(scales): numwords[word] = (10 ** (idx * 3 or 2), 0)
current = result = 0
for word in textnum.split():
if word not in numwords:
raise Exception("Illegal word: " + word)
scale, increment = numwords[word]
current = current * scale + increment
if scale > 100:
result += current
current = 0
return result + current
# print definitions
def printLoop(**dKeywordParameters):
if len(dKeywordParameters) == 0:
print "for vLoopVar in lLoopList:"
print "\t#some loop stuff:"
if 'iLoopVar' in dKeywordParameters and 'sLoopVar' not in dKeywordParameters:
print "Number of times provided, but no loop structure provided. I'll give you a standard range() for loop:"
print "for vLoopVar in range(0, " + str(dKeywordParameters['iLoopVar']) + "):"
print "\t#some loop stuff:"
if 'sLoopVar' in dKeywordParameters and 'sLoopStructureVar' in dKeywordParameters:
print "for " + sLoopVar + " in " + sLoopStructureVar + ":"
print "\t#some loop stuff:"
def printClassSkeleton(**dKeywordParameters):
if len(dKeywordParameters) == 0:
print "class Dog:\n\
\n\
def __init__(self, name): \n\
self.name = name \n\
self.tricks = [] # creates a new empty list for each dog \n\
\n\
def add_trick(self, trick): \n\
self.tricks.append(trick)"
if 'constructor' in dKeywordParameters:
print "class Dog:\n\
\n\
def __init__(self, name): \n\
self.name = name \n\
self.tricks = [] # creates a new empty list for each dog \n\
\n\
def add_trick(self, trick): \n\
self.tricks.append(trick)"
# arrays that we will use to sort the parts of speech further down
aVerbsPOS = ['VB','VBD','VBG','VBN','VBP','VBZ']
aNounsPOS = ['NN', 'NNS', 'NP', 'NPS']
aDeterminersPOS = ['DT']
aIndicatorsPOS = ['IN']
bThatContext = False # exterior context relating to previous statement made by bot
### PROGRAM PROCESS ###
# get user input
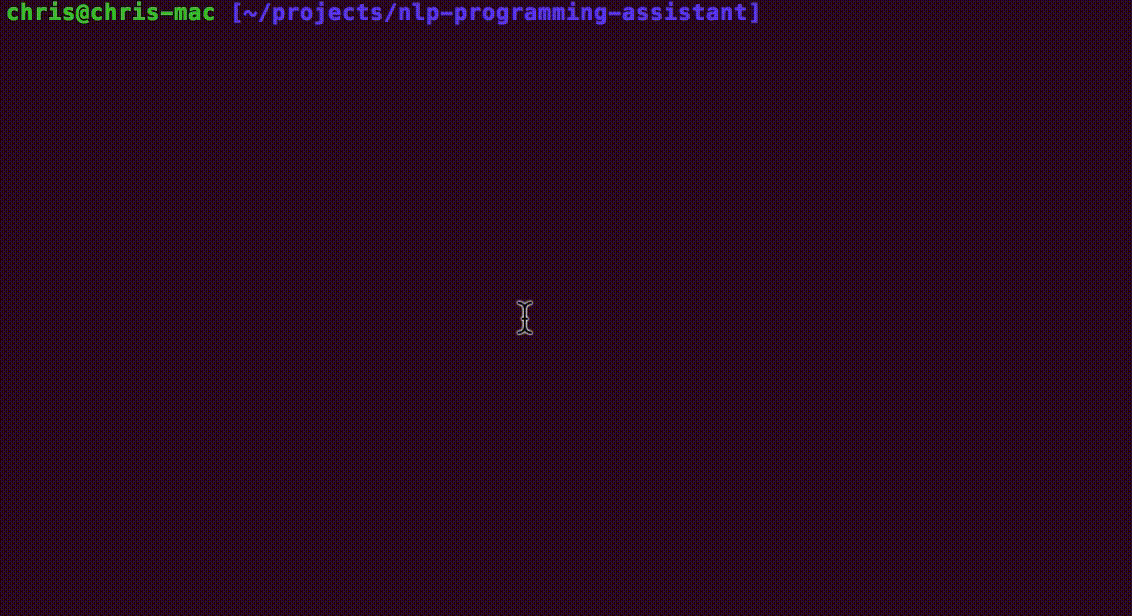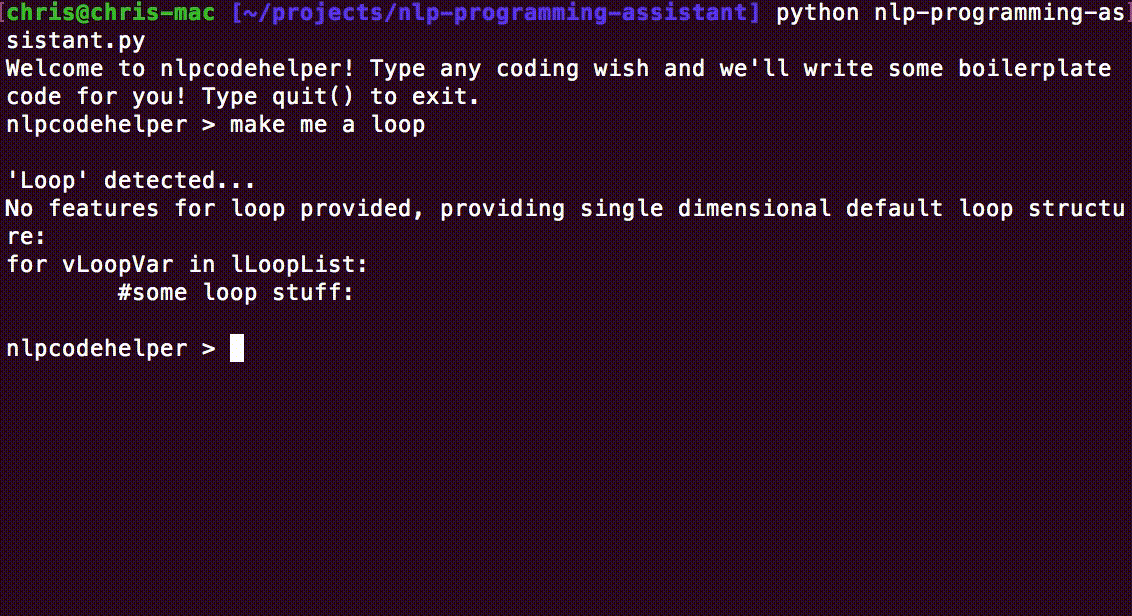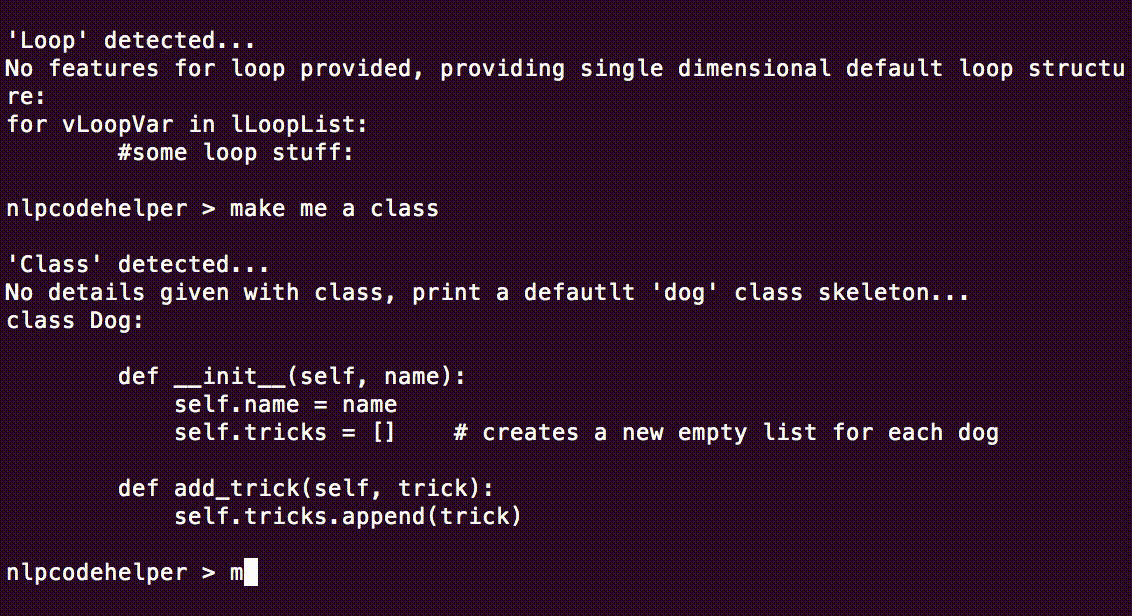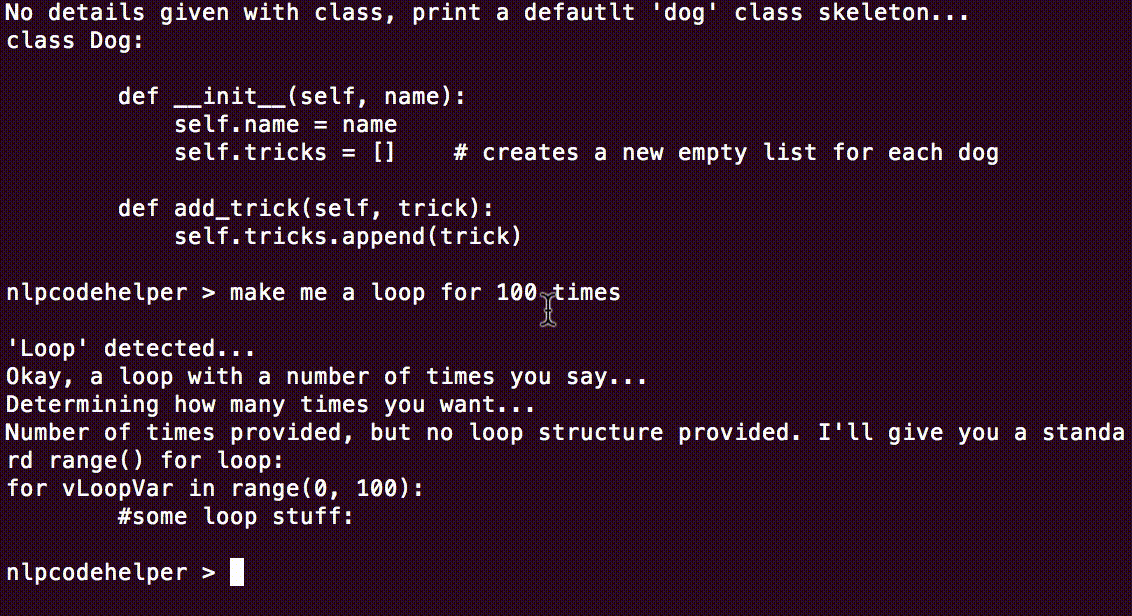
print "Welcome to nlpcodehelper! Type any coding wish and we'll write some boilerplate code for you! Type quit() to exit."
while True:
sInput = raw_input("nlpcodehelper > ")
# print empty space for prettier format
print " "
# allow user to quit with quit()
if sInput == "quit()":
print "Quitting..."
break
# tokenize and tag input
lTokenText = nltk.word_tokenize(sInput) # tokenize text
lTaggedText = nltk.pos_tag(lTokenText) # tag tokens
# rule based determination of what to do
lVerbs = [tTaggedText[0] for tTaggedText in lTaggedText if tTaggedText[1] in aVerbsPOS]
lNouns = [tTaggedText[0] for tTaggedText in lTaggedText if tTaggedText[1] in aNounsPOS]
lDeterminers = [tTaggedText[0] for tTaggedText in lTaggedText if tTaggedText[1] in aDeterminersPOS]
lIndicators = [tTaggedText[0] for tTaggedText in lTaggedText if tTaggedText[1] in aIndicatorsPOS]
print lIndicators
print lTaggedText
print lNouns
print bThatContext
### loop printing logic ###
if 'loop' in lNouns:
print "'Loop' detected..."
if 'times' in lNouns:
print "Okay, a loop with a number of times you say..."
print "Determining how many times you want..."
iTimesWordIndex = lTokenText.index('times')
iLoopVar = lTokenText[iTimesWordIndex - 1] # assume number is before word times
try:
iLoopVar = int(iLoopVar) # convert since it will be string type
except ValueError:
print "Loop number type string was not written as convertable int type! Attempting to convert..."
try:
iLoopVar = text2int(iNumber)
except FormatError:
print "String number of times was not in a good format! It must be grammatically correct: Ex. 'twenty two', 'thirty five', 'one hundred one', 'one hundred and one', etc."
printLoop(iLoopVar=5)
elif 'loop' in lNouns:
print "No features for loop provided, providing default loop structure:"
printLoop()
### class printing logic ###
elif 'class' in lNouns:
print "'Class' detected..."
if 'constructor' in lNouns:
print "Okay, 'constructor' was detected, attempting to build a constructor to your liking..."
if 'parameters' in lNouns:
iParameterWordIndex = lTokenText.index('parameters')
sParametersVar = lTokenText[iParameterWordIndex + 1] # assume number is before word times
else:
print "No details given with class, print a defautlt 'dog' class skeleton..."
printClassSkeleton() # print the class skeleton with no parameters
### angry / happy user context handling ###
elif 'that' in lIndicators: # ask user
bThatContext = True
print "By 'that' do you mean what I previously printed?"
elif 'yes' in lNouns and bThatContext == True:
bThatContext = False
print "Oh, I'm sorry I didn't print what you wanted... can you rephrase what you want me to print then?"
elif 'no' in lDeterminers and bThatContext == True:
bThatContext = False
print "Oh, ok then, I'm not sure I understand..."
else: # didn't go into ANY block
print "Sorry, I don't know you mean. Can you try a different question or rephrasing?"
# another empty between next call
print " "Yep, that’s it. As always, check out the most up-to-date code at GitHub! How did I keep it so short? Well, It’s a lot of rule based stuff and dynamic variables, that’s for sure. As I said in the intro, eventually I see each case in the processing not as a static print of a block of code but a call (with the options provided from the user) to one of many neural networks - each that were trained for various boilerplates. Then, also adding voice recognition in addition to text input - that is another task ahead. We will definitely revisit this code in future posts. But the groundwork is laid.
If you’re interested in working on this with us - definitely send us an email or leave a comment!